
Recently I had to try to pick up kafka and run it at a pretty reasonable scale(TB/hour). I’m still learning things, but my service is staying up and I have hit a nice checkpoint where it’s a good idea to write down what I think I know.
Kafka 101
- A kafka server is called a broker
- The unit of storage in kafka is called a partition.
- Data is written to topics by producers and read from it by consumers
- A topic consist of one or more partitions.
- Each record written to a partition is assigned a sequential id, an offset
- Consumers keep track of where they are within a partition by way of an offset. This offset is often persisted via the __consumer_offsets topic.
- Replication occurs via consumers
- Kafka stores information that needs high consistency inside zookeeper – this varies by version, but typically: controller election, broker registration / cluster membership, dynamic configuration including topic configuration, acls, and quotas.
- In older versions of kafka (0.x) the broker and consumer/producer versions need to basically be in lockstep.
Things I wish I had known about Apache Kafka
Kafka is not a message queue
Kafka was first presented to me in a message queue trade study I came across between RabbitMQ(which I’ve had to run for Sensu) and Kafka. I’d thus always framed it as another MQ I had to maybe run. Here’s the problem: Kafka isn’t a message queue.
Kafka is a journaled streaming engine.
So… what’s the difference?
One good way of framing it is via networking. If a message queue is TCP, Kafka is Multicast. This isn’t a perfect analogy, but it frames things reasonably well.
Thus, in a message queue:
- some form of acknowledgement of receipt is available (guaranteed delivery)
- messages have timeouts
- messages are consumed when a recipient reads them
Which is very much like TCP. Ok, there are no sessions and there isn’t really a handshake, but there are acks and mechanisms for guaranteed delivery.
Contrast this with a streaming engine. In a streaming engine a producer writes to a stream, consumers read from it. Which is very much like multicast. You send your data off into the world and whoever wants to can go grab it. It’s broadcast only, without another channel you don’t really have mechanisms to know who got what.
Another way of thinking about this is in terms of reactive vs. imperative design. A message queue is an imperative design, you tell things what they should do. You issue commands. A streaming engine is reactive, you are watching a stream of events.

Events happen, you react to them or you don’t.
Kafka is journaled and persistent
It is journaled in that it maintains a transaction log and persistent in that it writes data(messages) to disk. You can think of the journal much like a filesystem journal – the log is circular and acts as ring buffer for a certain amount of time (2 days by default). A reference, or offset is maintained for every message and this moves forward linearly.

as producers write, the offset is incremented. Consumers read from a certain offset and maintain their own consumer_offset, their places in the stream.
For persistence, the messages themselves are shoved off into page cache to be eventually written to disk in the form of log segments. Probably by flusher threads. Kafka doesn’t really care. Kafka does not concern itself with disk.
Kafka prioritizes overall throughput
Specifically to the point where if a choice must be made over a write or a read, it will choose the write.
Kafka has no limits on the amount of disk it will use
Look, you told it to keep 2 days of data (or left it at the default), obviously you gave it enough disk. Disk is infinite, or rather kafka does not concern itself with disk.
Kafka is not clustered
Or at least not the way I typically think of a cluster. First of all, zookeeper is involved, and zookeeper is the joker cracking wise about what exactly do you mean by consistency. Leaving that aside, to me a cluster is a quorum type service – you have an odd number of machines, lose one, maintain quorum, everything is good. This isn’t Kafka. Don’t think about Kafka like this, think of Kafka as a collection of individual storage servers.
Producers write to partitions, and these partitions replicate. We tell our cluster of 3 nodes to maintain 2 replicas…
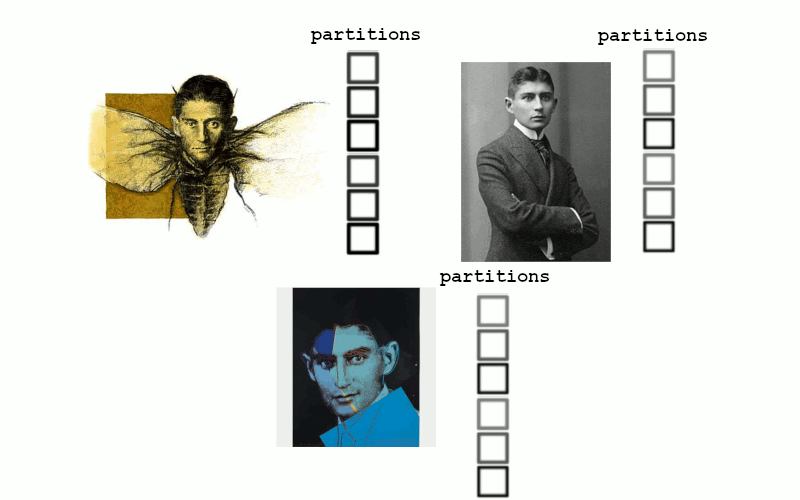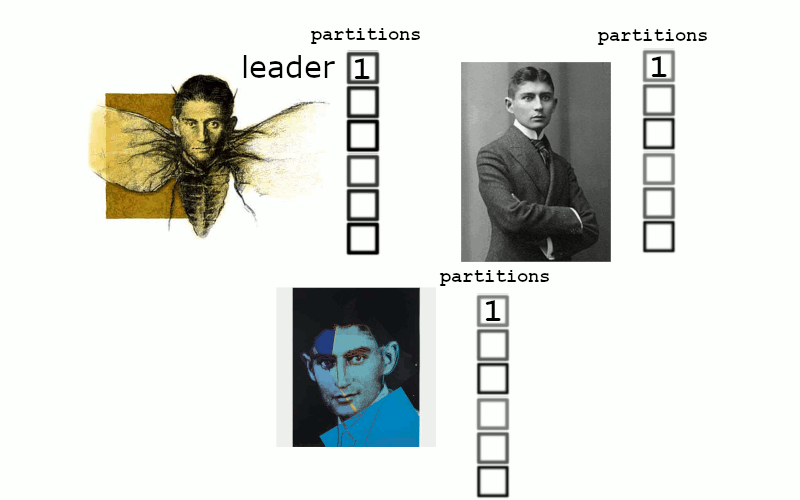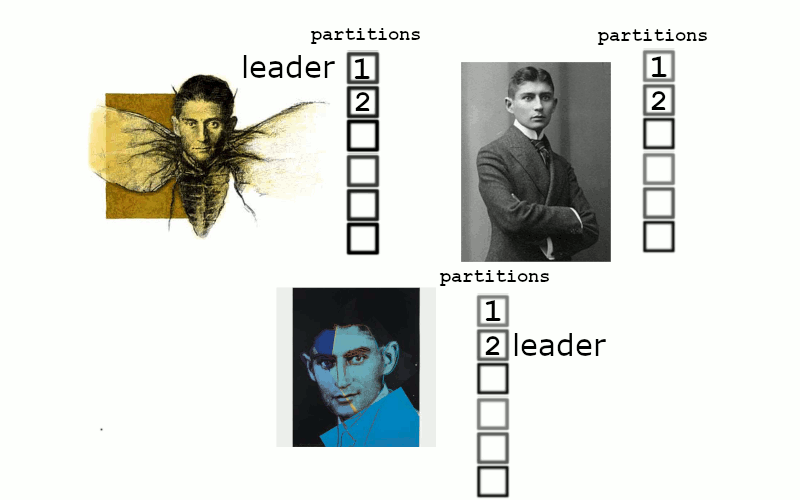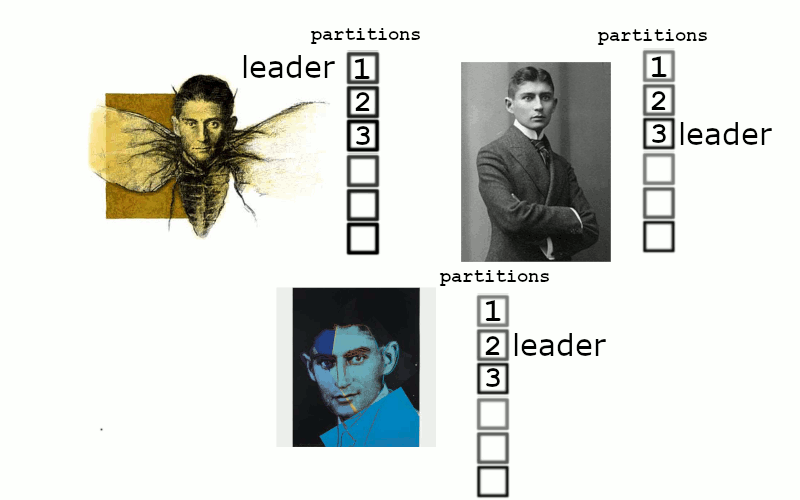
and everything is healthy. But if one server were to go down. We’re now in a situation where 1 kafka assumes leadership of 2 partitions, but there simply can’t be enough in sync replicas.
Things begin quickly accruing inside the two remaining kafka nodes, we can’t really write anything, but we still try. If this remediates quicky then replication occurs back to the primary node
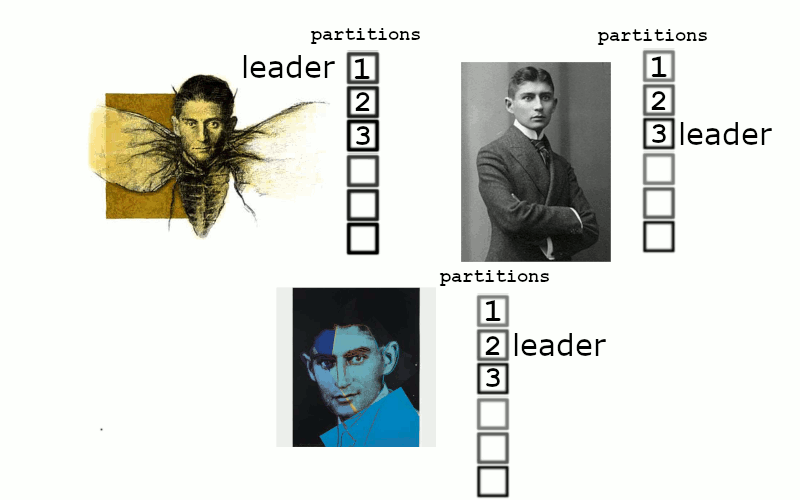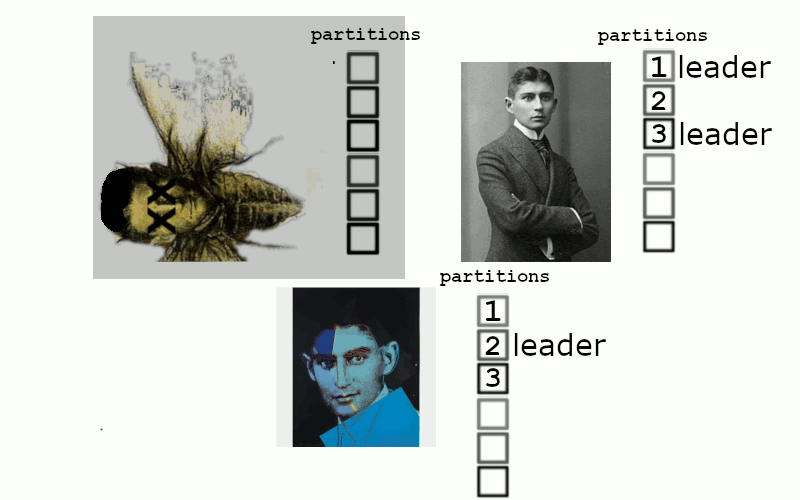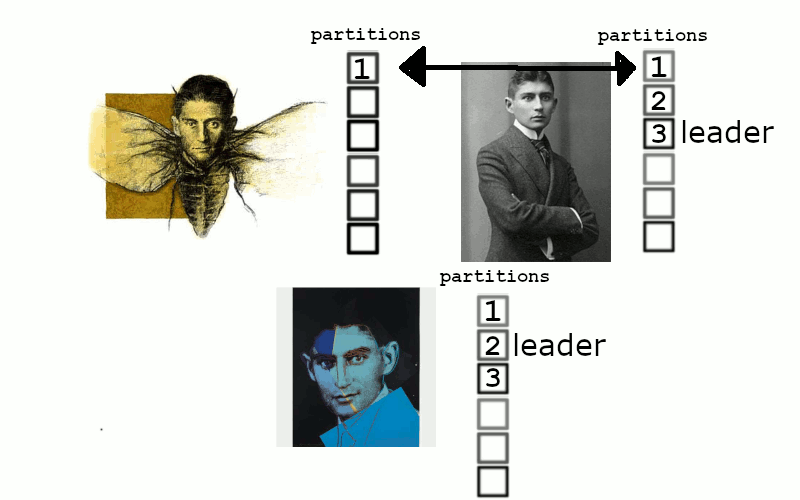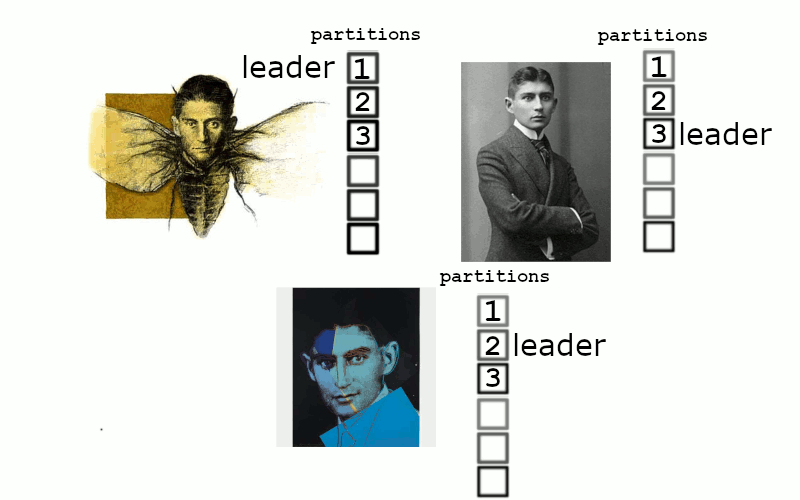
and everything is back to normal. If left down for too long, then eventually the buffers exhaust and the kafkas become sad
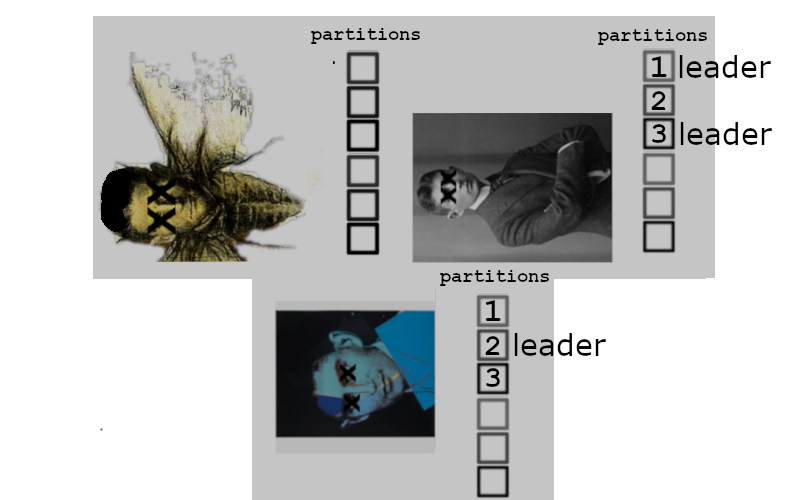
Thus when considering availability – your number of available servers has to exceed your required replica count. If we had had a 4th server in the above scenario then performance would have been impacted from replication, but the service would have stayed up.
There are tweaks you can make to this behavior: how many replicas need to respond to consumer / producer requests for a transaction to be committed, how many replicas a topic should have, etc. This represents a good overview of the defaults though.
Final Thoughts
There’s a lot more to running kafka well, especially at reasonable scales(as in terabytes an hour), and I hope to go through some of it in the coming days. Hopefully this has lain enough groundwork to do that, at least in regards to kafka itself.
There’s actually a lot to unwrap from here to do that. Kafka itself has a ton of tuneables that modify its behavior. Then on the OS side we’re looking at the right-hand side of the kernel map: vfs subsystem, page cache, a little bit of the network stack. The application itself is java, and so normal java things apply(compressed oops, monitoring GC, etc.) and a lot of visibility is gated behind JMX or requires additional tools to tap into it.